1. 분석 모형 설계
* 분석모형 선정 프로세스
- 문제요건 정의 – 데이터 수집·정리 – 데이터 전처리 – 분석 모형 선정
* 분석 모델링 설계와 검정-분석 목적에 기반한 가설검정 방법
① 유의수준 결정 귀무가설과 대립가설 설정
② 검정통계량 가설을 검정하기 위한 기준으로 사용하는 값의 설정
③ 기각역 설정
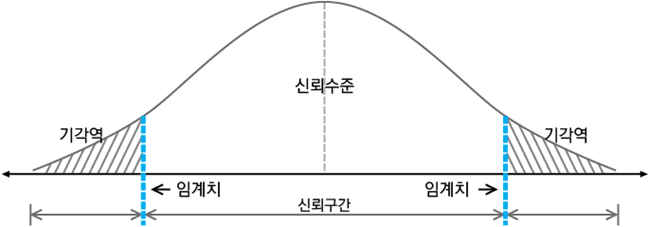
④ 검정통계량 계산
- 검정통계량
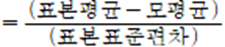
⑤ 통계적인 의사결정 가설검정
|
양측검정
|
• 귀무가설을 기각하는 영역이 양쪽에 있는 검정
• 대립가설이 가 아니다 크거나 작다 인 경우 사용 |
|
단측검정
|
• 귀무가설을 기각하는 영역이 한쪽 끝에 있는 검정
• 대립가설이 보다 작다 혹은 크다인 경우 사용 |
2. 분석 환경 구축
* 데이터 분할
- 학습 데이터 : 데이터를 학습하여 분석 모형을 만드는 데에 직접 사용되는 데이터
- 평가 데이터 : 추정한 분석모델이 과대 · 과소적합인지 모형의 성능을 평가하기 위한 데이터
- 테스트 데이터 : 최종적으로 일반화된 분석 모형을 검증하는 테스트를 위한 데이터
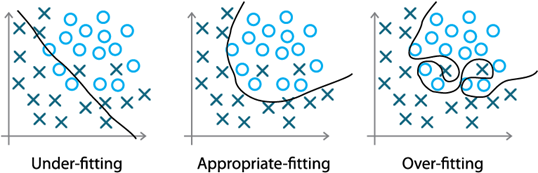
* 과대적합(과적합)
① 과대적합(과적합) : 학습 데이터에 대해서는 높은 정확도를 나타내지만 테스트 데이터나 새로운 데이터에
대해서는 예측을 잘 하지 못하는 것
- 과대적합 방지기법
+ 데이터 분할, K-fold 교차검증, 정규화 등
② 과소적합 : 모형이 단순하여 데이터 내부의 패턴 또는 규칙을 잘 학습하지 못하는 것
③ 일반화 : 학습 데이터를 통해 생성된 모델이 평가 데이터를 통한 성능 평가 외에도 테스트 데이터를 통해
정확하게 예측하는 것
3. 분석기법 적용
* 학습 유형에 따른 데이터 분석 모델
|
지도학습
|
주어진 데이터에 대해 정답을 부여하고 동일한 정답이 나오도록 분류 또는 새로운 데이터의
정답을 예측하도록 학습 - 분류 : 이미지 인식, 음성인식, 신용평가, 불량예측, 원인발굴 등 + 의사결정나무, 랜덤 포레스트, 인공신경망, SVM, 로지스틱 회귀분석 - 회귀 예측 : 시세/가격/주가 예측, 강유량 예측 등 + 의사결정나무 선형 회귀분석 , 다중 회귀분석 |
|
비지도학습
|
정답없이 컴퓨터 스스로 입력 데이터의 패턴을 찾아내고 구조화
- 군집분석 : 토픽분석, 고객 세그멘테이션 - 오토인코더 : 다차원 데이터를 저차원으로 바꾸고, 다시 고차원으로 바꾸면서 특징점 탐색 + 라벨이 설정되어 있지 않은 학습데이터로 학습 + 이상징후 감지, 노이즈 제거, 텍스트 벡터화 등 - 연관성 분석, 인공신경망 |
|
준지도학습
|
효율적 학습을 위해 목표값이 표시된 데이터와 그렇지 않은 데이터를 모두 학습에
사용함으로써 주어진 데이터 특징을 표현하는 잠재변수를 찾음 - 셀프 트레이닝 - 생성적 적대 신경망(GAN) : 두 개의 인공신경망으로 구성된 딥러닝 이미지 생성 알고리즘, 공방전 반복 |
|
강화학습
|
보상을 통한 학습
- 게임 플레이어 생성, 로봇 학습 알고리즘, 공급망 최적화 등 - Q Learning, 정책경사(PG) |
- 애노테이션 : 데이터상의 주석 작업. 학습 알고리즘이 어떤 것을 학습해야 하는지 알려주는 표식작업
* 다변량 데이터 탐색

|
독립변수
|
종속변수
|
분석방법
|
|
범주형
|
범주형
|
빈도분석, 카이제곱검정, 로그선형모형
|
|
연속형
|
범주형
|
로지스틱 회귀분석
|
|
범주형
|
연속형
|
t검정(2그룹), 분산분석(2그룹 이상)
|
|
연속형
|
연속형
|
상관분석, 회귀분석
|
① 빈도분석 : 질적자료를 대상으로 빈도와 비율을 계산할 때 쓰임
② 카이제곱검정 : 두 범주형 변수가 서로 상관이 있는지 독립인지를 판단하는 통계적 검정 방법
③ 로지스틱 회귀분석 : 분석하고자 하는 대상들이 두 집단 또는 그 이상의 집단으로 나누어진 경우 개별
관측치들이 어느 집단으로 분류될 수 있는지 분석할 때 사용
④ T검정 : 독립변수가 범주형(두 개의 집단)이고 종속변수가 연속형인 경우 사용되는 검정 방법
⑤ 분산분석 : 독립변수가 범주형(두 개 이상 집단)이고 종속변수가 연속형인 경우 사용되는 검정 방법
4. 회귀분석
* 전제조건
- 특정 독립변수값 갖는 종속변수는 정규분포 이루어야 하며, 분산이 동일해야 한다.
- 종속변수 값들은 서로 독립적이어야 한다.
- 독립변수가 여러개 일 경우 독립변수간 다중공선성(공차한계 VIF) 없어야 한다.
* 기본가정
- 독립변수와 종속변수 간의 선형성
- 오차의 정규성 : 관측치와 추정치의 차이. 발생하는 오차들은 평균 ‘0’의 정규분포를 따른다
- 오차의 등분산 가정 : 오차들의 분산은 X의 모든 값에 걸쳐서 일정하다.
- 오차의 독립성 가정 : 오차들은 서로 독립적이다. y의 변화에 따라 오차들이 패턴이 생기면 안된다.
- 회귀식을 이용하여 Y값 추정시 회귀식을 발견한 X의 범위 내에서만 가능하다.
* 다중회귀분석 결과 해석 순서
- 다중공선성 진단 → 회귀계수 유의성 확인 → 수정된 결정계수 확인 →모형의 적합도 평가
5. 로지스틱 회귀분석
* 로지스틱 회귀분석
① 종속변수가 이산형 유효한 범주의 개수가 두 개 일 때 사용
② 신용 평가에 많이 사용
6. 분산분석
* 분산분석(ANOVA)
- 각 모집단이 정규분포를 이루며 분산이 같은 세 개 이상의 집단들의 평균차이를 비교. 광고시안 4개
설문조사해서 평가가 차이가 있는지 조사하는 경우 활용
- 독립변수는 범주형, 종속변수는 연속형 척도
- 인자의 수준을 하나의 집단으로 가정한다. 집단과 집단이 얼마나 떨어져 있는지를 비교
- 그 외 어떤 실험변수에 여러 수준의 처치를 하고 그 결과가 다르게 나타나는지를 보는데도 많이 사용됨
* 일원분산분석(one-way ANOVA)
- 처치변수가 한 개, 종속변수도 1개인 분산분석. 광고시안(처치변수), 평가결과(결과변수)
* 이원분산분석(two-way ANOVA)
+ 처치변수가 2개, 종속변수 1개인 분산분석. 광고시안(처치변수1), 광고채널(처치변수2), 평가결과(결과변수)
* 다변량분산분석(MANOVA)
- 종속변수(결과변수)가 2개 이상인 분산분석
* 공변량분석(ANCOVA)
- 실험에서 얻어지는 다변량 자료들은 연속형 자료와 이산형 자료들이 혼합되어 있는 경우가 대다수
- 독립변수들이 이산형, 연속형 변수이고 종속변수가 연속형 자료인 경우로 분산분석과 회귀분석이 결합된
분석방법이다.
* 분산분석의 가정
① 관찰치는 서로 독립적 확률변수(무작위성)
② 각 모집단은 정규분포
③ 각 실험요소의 분산은 동일(등분산성)
7. 판별분석
* 판별분석
- 독립변수는 연속, 종속변수는 범주형인 변수간의 관계 분석
- 관측대상이 나타내는 변수를 이용하여 특정 대상이 어디에 속하는지 선형의 판별식을 구해 예측하는 것
- 고객의 분류, 기업도산여부 등을 판별하는데 사용
- 어느 집단에 속하는지, 분류하는데 어떤 변수가 중요한 역할을 하는지 분석하는 기법
- 집단 내 분산대비 집단 간 분산의 차이를 최대화 하는 독립변수들의 계수를 찾는 과정
* 다른 분석과의 차이점
- 판별분석 : 독립변수 연속형, 종속변수 명목. 사전에 집단이 나누어져 있음
- 회귀분석 : 독립, 종속변수 모두 비율척도인 변수간의 관계 분석
- 분산분석 : 독립변수 명목, 종속변수 비율로 판별분석과 반대
- 요인분석, 군집분석 : 종속변수 개념 없음
- 군집분석 : 사전에 집단이 나누어져 있지 않음
* 사용목적
- 중요변수파악 : 어떤 변수가 어떤 방향으로 얼마나 판별점수에 영향을 미치는지 파악한다.
- 분류 : 새로운 대상의 독립변수 값으로 판별식 계산하여 어느 범주에 속하는지 예측한다.
8. 의사결정나무
* 의사결정나무
- 의사결정 규칙을 나무 모양으로 조합하여 목표 변수에 대한 분류 또는 예측을 수행
- 부모마디 : 자식마디의 상위 마디
- 자식마디 : 하나의 마디로부터 분리된 2개 이상의 마디
- 가지 : 하나의 마디로부터 끝 마디까지 연결된 마디
- 깊이 : 가장 긴 가지를 이루는 마디의 개수
- 정지규칙 : 더 이상 분리가 일어나지 않고 현재의 마디가 끝마디가 되도록 하는 규칙
- 부모마디보다 자식마디의 순수도(purity) 증가, 불확실성은 감소하도록 분리 진행(정보 획득)
- 장점
+ 연속형, 범주형 변수 모두 적용, 변수 비교가 가능하며 규칙에 대해 이해하기 쉽다
+ 데이터로부터 규칙을 도축하는데 유용하므로 DB 마케팅, CRM, 시장조사, 기업부도/환율 예측 등 다양한 분야에
활용
- 단점
+ 트리구조가 복잡할 시 예측/해석력이 떨어짐
+ 데이터 변형에 민감
* 의사결정나무의 분석 과정
① 변수 선택 : 목표변수와 관련된 설명 독립 변수들을 선택
② 의사결정나무 형성 : 분석목적에 따라 적절히 훈련데이터를 활용
③ 가지치기 : 부적절한 추론규칙을 가지거나 불필요 또는 분류오류를 크게 할 위험이 있는 마디 제거
④ 타당성 평가 : 이익 비용 위험 등을 고려하여 모형을 평가
⑤ 해석 및 예측 : 최종 모형에 대한 해석으로 분류 및 예측 모델을 결정
* 의사결정나무 알고리즘
- CART : 일반적으로 활용되는 의사결정나무 알고리즘
+ 불순도 측도로 범주형 또는 이산형일 경우 지니 지수를, 연속형일 경우 분산의 감소량을 이용한 이진분리를 활용
- 랜덤 포레스트 : 여러개의 의사결정 나무를 활용하여, 분류 예측 결과를 투표 방식으로 예측을 결정
+ 부트스트래핑 기반 샘플링을 활용한 의사결정나무 생성 이후 배깅 기반 나무들을 모아 앙상블 학습하여 숲을 형성
※ 부트스트래핑 : 랜덤 샘플링으로 크기가 동일한 여러 개의 표본자료 생성
※배깅 : 같은 알고리즘 내에서 다른 표본 데이터 조합을 사용 샘플을 여러 번 뽑아 각 모델을 학습시켜 결과물을
집계
※부스팅(boosting) : 가중치를 활용해 연속적인 약학습기를 생성하고 이를 통해 강학습기를 만듦
- 순차적인 학습을 하며 가중치를 부여해서 오차를 보완, 병렬처리 어려움
9. 인공신경망
* 인공신경망
- 가중치 : 노드와의 연결계수
- 학습 : 손실함수값이 최소화 하기 위한 가중치와 편향을 훈련 데이터에 적응하도록 조정하는 과정
+ 손실함수 : 신경망이 출력한 값과 실제 값과의 오차에 대한 함수. 평균제곱오차 또는 교차 엔트로피 오차 활용
- 신경망 학습 프로세스 : 미니배치 →가중치 매개변수 기울기 산출 → 매개변수 갱신
- 오차역전파 : 오차를 출력층에서 입력층으로 전달, 연쇄법칙을 활용한 역전파를 통해 가중치와 편향을 업데이트
- 뉴런 연결방법
+ 층간연결 : 서로 다른 층에 존재하는 뉴런과 연결
+ 층내연결 : 동일 층 내의 뉴런과의 연결
+ 순환연결 : 어떠한 뉴런의 출력이 자신에게 입력되는 연결

* 딥러닝 모델 종류
- 합성곱 신경망(CNN)
+ 사람의 시신경 구조 모방. 모든 입력 데이터들을 동등한 뉴런으로 처리
+ 데이터의 특징, 차원을 추출하여 패턴을 이해하는 방식으로 이미지(벡터)의 특징을 추출하는 과정과 클래스를
분류하는 과정을 통해 진행
+ 특징 추출과정 : 합성곱 계층과 풀링 계층으로 나누어짐
- 순환 신경망(RNN)
+ 순서를 가진 데이터를 입력하여 단위 간 연결이 시퀀스를 따라 방향성 그래프를 형성하는 모델
+ 내부상태(메모리)를 이용하여 입력 시퀀스를 처리
+ 필기나 음성 인식과 같이 시변적 특징을 지니는 데이터 처리에 적용
- LSTM
+ 점차 데이터가 소멸되는 RNN 의 단점을 보완
+ 보통 신경망 대비 4배 이상 파라미터를 보유 여러 단계를 거쳐도 오랜 시간동안 데이터를 잘 기억
+ 입력게이트, 출력게이트, 망각게이트
- 오토인코더
+ 비지도학습모델. 다차원 데이터를 저차원으로 바꾸고, 다시 고차원으로 바꾸면서 특징점 탐색
+ 인공신경망 두 개(인코더, 디코더)가 뒤집어 붙은 형태
+ 인코더를 통해 입력 데이터에 대한 특징 추출
+ 입력으로 들어온 다차원 데이터를 인코더를 통해 차원을 줄이는 은닉층으로 보냄 → 은닉층의 데이터를
디코더를 통해 차원을 늘리는 출력층으로 내보냄 → 출력값을 입력값과 비슷해지도록 만드는 가중치를 찾는 것
- 생성적 적대 신경망(GAN)
+ 학습데이터 패턴과 유사하게 만드는 생성자 네트워크와 패턴의 진위 여부를 판별하는 판별자 네트워크가 서로의
목적을 달성하도록 학습 반복
+ 확률분포를 학습하는 생성모델과 서로 다른 집합을 구분하는 판별모델로 구성됨
→ 생성모델 : 가짜 예제를 만들어 판별모델을 최대한 속일 수 있도록 훈련
→ 판별모델 : 가짜 예제와 실제 예제를 최대한 정확하게 구분할 수 있도록 훈련
- 셀프트레이닝
+ 레이블이 달린 데이터로 모델을 학습한 뒤, 레이블 되지 않은 데이터를 예측하여 이 중에서 가장 확률이 높은
데이터만 테이블 데이터로 다시 가져감
10. 서포트 벡터 머신(SVM)
* 서포트벡터머신(SVM)
- 분류, 회귀, 특이점 판별에 사용되는 지도학습 기법
- 선형, 비선형 분류가 가능
- 예측 정확도가 높은 편이나 처리속도가 느림
- 고차원 또는 무한차원의 공간에서 초평면의 집합을 찾아 이를 이용하여 분류와 회귀를 수행
- 핵심 특징
+ 기존분류기는 오류를 최소화에 중점을 두나 SVM은 여백(마진) 최대화로 일반화 능력의 극대화를 추구
+ 마진이 가장 큰 초평면을 분류기로 사용할 때 새로운 자료에 대한 오분류가 가장 낮아짐
- 경계면과 수직인 법선벡터를 w라고 할 때 마진은 1/(|W|)로 계산됨
* 주요 용어
① 벡터 : 점들 간 클래스
② 초평면 : 서로 다른 분류에 속한 데이터들 간 거리를 가장 크게 하는 분류 선
③ 서포트벡터 : 두 클래스를 구분하는 경계
④ 마진 : 서포트벡터를 지나는 초평면 사이의 거리
11. 연관성 분석

* 아프리오리(Apriori) 알고리즘
- 연관 규칙 분석을 위한 연관분석 알고리즘. 발생빈도를 기반으로 각 데이터간의 연관관계를 밝히기 위한 방법
+ 연관규칙 : 항목들 간 ‘조건-결과’식으로 표현되는 유형의 패턴.
- 세분화된 품목, 데이터의 최소 지지도를 설정해 주어야 함
+ 최소 지지도 설정
+ 개별 품목 중에서 최소 지지도를 넘는 모든 품목 찾기
+ 위에서 찾은 개별 품목만을 이용하여 최소 지지도를 넘는 두가지 품목의 집합 찾기
+ 위 두 절차에서 찾은 품목 집합을 결합하여 최소지지도를 넘는 세가지 품목 집합을 찾기
+ 반복적으로 수행해 최소지지도가 넘는 반발품목집합을 찾기
12. 군집분석


* 계층적, 비계층적 군집분석
① 계층적 군집분석 : 계층화된 구조로 군집을 형성, 군집 수 명시 불필요, 덴드로그램 통해 결과 표현
- 최단, 최장, 평균, Ward 연결법, 계층적 병합 군집화
② 비계층적 군집분석 : 사전 군집 수로 표본을 나누며 레코드들을 정해진 군집에 할당, 적은 계산량으로 대규모
DB에서 처리가 유용
- K-평균 군집 분석
13. 다차원척도법(MDS)
* 다차원척도법(MDS)
- 여러 대상들의 유사성을 지각에 관한 정보로부터 대상들을 시각적으로 나타냄
- 대상들의 위치로부터 유사성 지각의 토대가 된 차원들을 추정하는 기법
- 포지셔닝 분석을 통계적으로 하기 위해 쓰이는 방법론으로 하나의 알고리즘이 아니라 시각화까지 나타내는
방법론이다. 지각도를 그려 경쟁상황과 이상점과의 차이를 비교해 볼 수 있도록 하는 방법이다.
- 개체간의 거리/차이 또는 유사성이 주어셨을 때 공간에 나타내어 전반적인 데이터 구조를 그릴 수 있도록 한다.
14. 다변량분석
* 다변량분석
① 다중회귀분석 : 다수의 독립변수 변화에 따른 종속변수의 변화를 예측
② 다변량분산분석 : 두 개 이상의 범주형 독립변수와 다수의 계량적 종속변수 간 관련성을 동시에 알아볼 때
이용되는 통계적 방법
- 두 개 이상의 계량적 종속변수에 대한 각 집단의 반응치의 분산에 대한 가설을 검증하는데 매우 유용
③ 다변량공분산분석 : 실험에서 통제되지 않은 독립변수들의 종속변수들에 대한 효과를 제거하기 위해
이용되는 방법
④ 정준상관분석 : 종속변수군과 독립변수군 간의 상관을 최대화하는 각 변수군의 선형조합을 찾음
- 두 변수 집단간의 연관성을 각 변수집단에 속한 변수들의 선형결합의 상관계수를 이용하여 분석하는 방법
- 정준상관계수는 정준변수들 사이의 상관계수
- 두 집단에 속하는 변수들의 개수 중에서 변수의 개수가 적은 집단에 속하는 변수의 개수만큼 정준변수의
상이 만들어질 수 있음(최적의 인과를 찾는 것이 아님)
⑤ 요인분석 : 많은 변수들 간 상호관련성을 분석하고 어떤 공통 요인들로 설명하고자 할 때 이용
⑥ 군집분석 : 집단에 관한 사전정보가 전혀 없는 각 표본에 대하여 그 분류체계를 찾음
⑦ 다중판별분석 : 종속변수가 비계량적 변수인 경우, 집단 간 차이를 판별하며 어떤 사례가 여러 개의 계량적
독립변수에 기초하여 특정 집단에 속할 가능성을 예측하는 것이 주목적
⑧ 다차원척도법 : 개체들을 원래의 차원보다 낮은 차원의 공간상에 위치시켜 개체들 사이의 구조 또는 관계를
쉽게 파악하는 목적
15. 시계열분석
* 시계열 분석
- 불규칙성분 : 시간에 따른 규칙적인 움직임이 없는 랜덤하게 변화하는 변동성분
- 추세성분 : 관측값이 지속적으로 방향을 가지고 움직이는 것
- 계절성분 : 주기를 가지고 움직이는 것
- 순환성분 : 주기적 변화를 가지나 계절적인 것이 아닌 주기가 긴 변동을 가지는 형태
- 복합성분 : 추세성분과 계절성분을 동시에 가지는 것
- 자기상관성 : 시계열데이터에서 시차값들 사이에 선형관계를 보이는 것
- 백색잡음 : 자기 상관성이 없는 시계열 데이터. 아무런 패턴이 남아있지 않은 무작위 움직임(진동)
* 정상성(stationarity)
- 시계열 데이터가 평균과 분산이 일정한 경우, 분석이 용이한 형태
- 모든 시점의 평균과 분산이 일정, 공분산이 시차에만 의존, 정상시계열은 평균회귀 경향을 가짐
- 시계열데이터가 평균이 일정하지 않으면 차분을 통해 정상성을 가지도록 할 수 있음
- 시계열데이터가 분산이 일정하지 않으면 변환을 통해 정상성을 가지도록 할 수 있음
* 시계열 자료의 대표 분석 방법
① 단순 방법
- 이동평균법 : 일정기간을 시계열을 이동하며 평균을 계산
- 지수평활법 : 관찰기간 제한 없이 모든 시계열 데이터를 사용, 최근 시계열에 더 많은 가중치를 줌
- 분해법 : 시계열 자료의 성분 분류대로 분해하는 방법
② 모형기반 방법
- 자기회귀모형(AR) : 과거의 패턴이 현재자료에 영향을 준다는 가정
+ 일정 시점전의 자료가 현재자료에 영향을 준다는 가정하에 만들어진 시계열예측모형
- 자기회귀이동평균모형 : AR(p) 모형과 MA(q) 모형의 결합형태
- 자기회귀누적이동평균모형(ARIMA) : 비정상성을 가지는 시계열 데이터 분석에 많이 사용됨
16. 베이즈 기법
* 베이즈 기법
① 회귀분석모델 적용 : 추정치와 실제의 차이를 최소화하는 것이 목표
② 나이브 베이즈 분류
- 분류기를 만들 수 있는 간단한 기술. 단일 알고리즘을 통한 훈련이 아닌 일반적인 원칙에 근거한 여러
알고리즘들을 이용하여 훈련됨
- 분류에 필요한 파라미터를 추정하기 위한 학습 데이터의 양이 매우 적음
- 간단한 디자인, 지도학습 환경에서 효율적
- 나이브 베이즈 분류기는 공통적으로 모든 특성 값은 서로 독립임을 가정

17. 딥러닝 분석
* 딥러닝 분석
① 인공신경망 : 시냅스의 결합으로 네트워크를 형성한 인공 뉴런(노드)이 학습을 통해 시냅스의 결합 세기를
변화시켜 문제 해결 능력을 가지는 모델 전반
② 심층 신경망(DNN) : 입력층과 출력층 사이에 여러 개의 은닉층들로 이루어진 인공 신경망
③ 합성곱 신경망(CNN) : 최소한의 전처리를 사용하도록 설계된 다계층 퍼셉트론의 한 종류
④ 순환 신경망(RNN) : 인공 신경망을 구성하는 유닛 사이의 연결이 directed cycle을 구성
- 순방향 신경망과 달리, 임의의 입력을 처리하기 위해 신경망 내부의 메모리를 활용할 수 있다
- 필기체 인식과 같은 분야에 활용, 높은 인식률
- 기존의 뉴럴 네트워크와 다른점은 ‘기억’을 가지고 있다는 점. 네트워크의 기억은 지금까지의 입력 데이터를
요약한 정보
⑤ 심층 신뢰 신경망(DBN) : 잠재변수의 다중계층으로 이루어진 심층 신경망
18. 비정형 데이터 분석
* 비정형 데이터 분석
① 비정형 데이터 분석 기본 원리 : 비정형 데이터의 내용 파악과 패턴 발견을 위해 다양한 기법 활용, 정련
과정을 통해 정형 데이터로 만든 후 데이터 마이닝을 통해 의미있는 정보 발굴
② 데이터 마이닝 : 데이터 안에서 통계적 규칙이나 패턴을 분석하여 가치 있는 정보 추출
- 텍스트 마이닝, 자연어 처리, 웹 마이닝, 오피니언 마이닝, 리얼리티 마이닝
- 리얼리티 마이닝 : 통화/메시징 등의 커뮤니케이션 데이터, GPS/wifi 등의 위치 데이터 등을 통해 사회적 행위를
마이닝, 사용자 행동 모델링이나 라이프 로그를 얻는 것을 목표
* 비정형 데이터
- 데이터 마이닝
+ 체계적이고 자동적으로 통계적 규칙이나 패턴을 분석하여 가치 있는 정보를 추출하는 과정
+ 자료에 의존하여 현상을 해석하므로 자료가 현실을 충분히 반영하지 못한 상태인 경우 잘못된 모형을 구축하는
오류를 범할 수 있음
- 텍스트 마이닝
+ 인간의 언어로 이루어진 비정형 텍스트 데이터들을 자연어 처리방식을 이용하여 숨겨진 의미를 발견하는 기법
- 오피니언 마이닝
+ 텍스트 마이닝의 한 분류, 특정 주제에 대한 사람들의 주관적 의견을 통계·수치화해 객관적 정보로 바꾸는 기술
+ 텍스트 마이닝은 문장 내 주제 파악 오피니언 마이닝은 감정·태도 판별
- 웹 마이닝
+ 웹으로 통한 모든 것(로그, 사용자 행동 및 작성 콘텐츠 등)을 분석하여 유용한 정보를 추출하는 것
- 자연어 처리 : 인간의 언어 현상을 컴퓨터를 이용하여 모사할 수 있도록 연구하고 구현하는 인공지능 분야
19. 앙상블 분석
* 앙상블 분석
― 동일한 학습 알고리즘을 사용해서 여러 모델을 학습하는 개념
① 주어진 자료로부터 여러 개의 학습 모형을 만든 후 조합하여 하나의 최종 모형을 만드는 개념
② 약학습기를 통해 강학습기를 만들어내는 과정
- 약학습기 : 무작위 선정이 아닌 성공률이 높은(오차율이 50% 이하) 학습 규칙
- 강학습기 : 약학습기로부터 만들어내는 강력한 학습규칙
* 앙상블 분석의 종류
① 보팅(voting) : 서로 다른 알고리즘 모델을 조합해서 사용, 결과물에 대해 투표로 결정
- 소프트 보팅 : 최종 결과물이 나올 확률값을 다 더해서 최종 결과물에 대한 각각의 확률을 구한 뒤 최종값을
도출해 내는 방법
- 하드 보팅 : 결과물에 대한 최종 값을 투표로 해서 결정하는 방식
② 부스팅(boosting) : 가중치를 활용해 연속적인 약학습기를 생성하고 이를 통해 강학습기를 만듬
- 순차적인 학습을 하며 가중치를 부여해서 오차를 보완, 병렬처리 어려움
- 분류모델이 틀린 곳에 집중하여 새로운 분류규칙을 생성, 즉, weak classifier에 중점을 두는 지도학습 알고리즘
③ 배깅(bagging) : 같은 알고리즘 내에서 다른 표본 데이터 조합을 사용 샘플을 여러 번 뽑아 각 모델을
학습시켜 결과물을 집계 → 랜덤 포레스트
20. 비모수 통계
* 비모수 통계
- 통계학에서 모수에 대한 가정을 전제로 하지 않고 모집단의 형태에 관계없이 주어진 데이터에서 직접 확률을
계산하여 통계학적 검정을 하는 분석
- 모집단의 형상이 정규분포가 아닐 때, 표본이 적을 때, 자료들이 서로 독립적일 때
- 질적 척도로 측정된 자료도 분석 가능, 비교적 신속하고 쉽게 통계량 구할 수 있고 해석의 이해도 용이
- 가정을 만족시키지 못한 상태에서 그대로 모수통계분석을 함으로써 발생할 수 있는 오류를 줄일 수 있음
- 많은 표본을 추출하기 어려운 경우에 사용하기 적합
- 비모수 통계검정
+ 부호검정 : 관측치들간에 같다, 크다, 작다 라는 주장이 사실인지를 검증
+ 윌콕슨 부호순위 검정 : 크거나 작음을 나타내는 부호뿐만 아니라 관측치 간 차이의 크기 순위까지 고려
+ 만 휘트니 검정 : 두 집단간 중심위치를 비교하기 위한 방법
+ 크루스칼-왈리스 검정 : 3개 이상 집단의 중앙값 차이를 검정
'상상의 창 블로그 > 배움의 창' 카테고리의 다른 글
| 일반인의 투자에 대하여(24.01.17) (1) | 2024.05.31 |
|---|---|
| [빅데이터분석기사] 4. 결과해석 (0) | 2024.05.30 |
| [빅데이터분석기사] 2. 데이터 탐색 (1) | 2024.05.30 |
| [빅데이터분석기사] 1. 빅데이터 분석기획 (0) | 2024.05.30 |
| 케글연습 첫날 (22.08.23) (0) | 2024.05.30 |


